From ReAct Loops to Deep Agents: What Changed
We weren't looking for a new framework. We were looking for a way out of patterns we kept hitting.
We weren't looking for a new framework. We were looking for a way out of patterns we kept hitting.
The Demo That Didn't Tell the Whole Story
ReAct-based agents looked great in demos. Give the agent a task, watch it reason through steps, call tools, return a result. Simple, transparent, works.
Then we started running real marketing workflows at Rohlik — multi-step tasks, tool-heavy, time-sensitive, spanning multiple domains. The cracks appeared fast.
The agent would start executing before it understood the full scope of the work. By step 8 of a 12-step workflow, it would contradict decisions it made at step 2. Give it a task that involved both product discovery and recipe creation, and it would tangle the two domains into an incoherent mess. We'd watch it call the same tool three times in a row, get the same result, and call it again.
We weren't debugging the model. We were debugging the framework.
Three Failure Modes That Kept Coming Back
Context rot. ReAct agents accumulate turn history as they work. On long-running tasks, earlier constraints gradually fall out of effective attention. The agent that correctly noted "only update published recipes" at step 1 would quietly ignore that constraint by step 10. Not a model failure — a context management failure.
Tool loop drift. Without a planning step, agents start calling tools immediately. They get partial results, call more tools to fill in gaps, get more partial results, and spiral. No mechanism forces them to stop, assess what they know, and decide what to do next. The loop runs until the recursion limit or until something accidentally converges.
Monolithic orchestration. A single graph handling every workflow type. Adding a second workflow meant either duplicating the logic or tangling it with the first. No clean way to say "this task belongs to the chef agent, that task belongs to the product agent." Everything shared the same context, the same tools, the same failure surface.
These weren't fixable by tweaking the system prompt. They were architectural.
What Deep Agents Changed
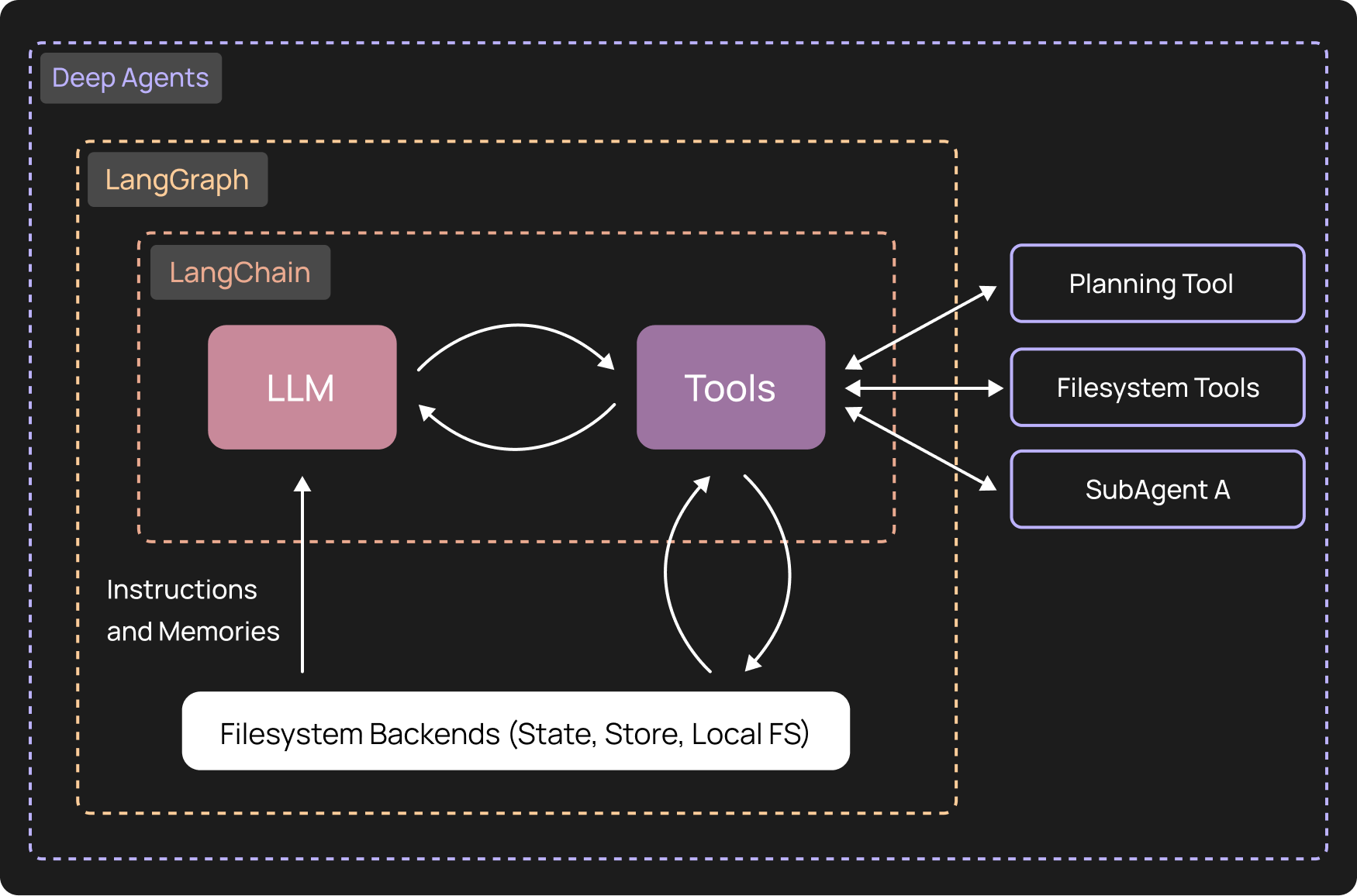
Deep Agents is an open-source framework built by LangChain on top of LangGraph. It extracted the patterns behind tools like Claude Code and made them available with any model. The name reflects the distinction: "shallow" agents loop through tools, "deep" agents plan, delegate, and manage their own context.
Three things changed immediately when we moved to it.
A planning step before execution. Deep Agents includes a write_todos tool — a no-op that forces the agent to articulate its complete plan before touching any real tools. This is the same pattern Claude Code uses internally. The agent writes out every step it intends to take, then executes. Tool loop drift disappeared almost entirely. Agents that plan first converge; agents that don't, spiral.
Automatic context management. Large tool outputs are compressed and written to files automatically. The agent receives a summary instead of raw history. This is infrastructure the framework handles invisibly — we stopped manually tuning context window usage and started trusting that long-running tasks would stay coherent. For workflows that routinely run 15–20 tool calls, this matters.
Sub-agent isolation. Deep Agents natively supports specialist sub-agents with clean, isolated contexts. Recipe work routes to the chef agent. Product discovery routes to the product agent. Microsite management goes somewhere else entirely. Each agent gets exactly the context it needs for its domain — nothing more. The monolithic orchestration problem dissolved into a routing problem, which is much easier to reason about.
One more thing worth naming: model-agnosticism. Deep Agents works with any LLM that supports tool calling — Anthropic, OpenAI, Gemini, local models via LiteLLM. We run Claude in production today. If that changes — pricing, capability, data residency requirements — we swap the model configuration. Zero framework rewrite.
When Claude Agent SDK Still Wins
That said, the comparison isn't one-sided.
If a team is fully committed to Claude and wants the tightest native integration, the Claude Agent SDK is the right call. Anthropic's permission and safety models are baked in by default, not layered on. Setup is simpler — fewer configuration choices means fewer ways to misconfigure.
For teams building on Claude with no plans to change, the friction of model-agnosticism is overhead paid for flexibility that won't get used.
| Deep Agents | Claude Agent SDK | |
|---|---|---|
| Model provider | Any (100+) | Claude only |
| Execution backend | Pluggable | Local sandbox only |
| Custom / local LLM | ✅ | ❌ |
We operate across multiple European markets with varying infrastructure constraints. Model flexibility isn't hypothetical for us — it's a real operational requirement.
What Actually Changed
The framework didn't change what our agents could do. Same model, same tools, same workflows. It changed what we could do: debug faster because failure surfaces are smaller, update workflows without touching agent code, and hand domain-specific procedure maintenance to the teams who own those domains.
If this sounds familiar, it connects directly to what we wrote about in Context as Infrastructure: the framework handles execution, the skill layer handles knowledge. Two layers, one coherent system. Neither is interesting without the other.
The ReAct loop is still the right tool for short, focused, single-purpose tasks. For anything longer, anything that requires coherent multi-step planning, anything that spans domains — the shape of the problem demands a different shape of framework.